A practitioner's guide for CIOs, CDOs, and data platform leaders navigating the architecture decision that will define their organization's AI readiness. Why the future of enterprise data architecture is no longer about storage — but AI readiness, governance, and vendor optionality.
The Question Every Data Leader Is Still Asking — Incorrectly
In 2026, enterprise conversations around data architecture have evolved. Unfortunately, much of the thinking has not.
Many organizations still approach modern data platforms as a binary decision:
Data warehouse or data lake?
That framing is now outdated.
It has led to three predictable outcomes across the market:
- Over-engineered data lakes that degrade into ungoverned "data swamps" — a problem now largely solved at the technology layer by open table formats and metadata catalogs, yet still endemic where governance was never implemented
- Rigid enterprise warehouses that struggle to support AI and machine learning workloads
- Hybrid architectures assembled without clear operating principles — inheriting the weaknesses of both
The real question today is not which architecture is "best."
The real question is:
Which architecture best matches your workload mix, governance requirements, cost profile, and AI roadmap?
And increasingly, the answer is not a single platform — but a deliberately designed architecture built on open standards, with Apache Iceberg as the emerging default at the storage layer and an open catalog as the interoperability backbone.
This guide breaks down the modern landscape without vendor marketing spin and provides a practical framework for choosing the right approach in 2026.
1. Understanding the Three Architectures — Without the Buzzwords
A note on convergence: In 2026, the boundaries between these three architectures are blurring rapidly. Every major warehouse vendor now supports lakehouse patterns; every lakehouse platform now offers warehouse-grade SQL. The distinctions below remain useful for understanding design intent and tradeoffs — but most enterprises will end up with a hybrid that draws from multiple categories.
The Enterprise Data Warehouse
A data warehouse is a centralized analytics system optimized for structured reporting and repeatable SQL workloads.
Data is transformed before storage using schema-on-write modeling, creating highly governed and highly performant analytical environments.
Think of it as:
A meticulously organized filing cabinet:
- Everything has a predefined location
- Retrieval is extremely fast
- Adding new data structures requires planning and governance
Core characteristics
- Schema-on-write (though increasingly paired with schema-on-read at ingestion via medallion architecture patterns)
- Strong ACID guarantees
- Optimized for structured analytics
- Mature BI tooling ecosystem
- Traditionally bundled compute + storage (now universally decoupled across major platforms)
Typical platforms
- Snowflake (also supports lakehouse — see below)
- Google BigQuery (also supports lakehouse via Lakehouse for Apache Iceberg)
- Amazon Redshift (also supports lakehouse via native Iceberg + S3 Tables)
- Databricks SQL (warehouse built on lakehouse architecture)
- Microsoft Fabric Warehouse (successor to Azure Synapse Analytics)
- Teradata, Oracle Autonomous Data Warehouse
Best suited for
- Executive dashboards
- Financial reporting
- Regulatory workloads
- Predictable BI queries
- Governance-heavy industries
The Data Lake
A data lake stores raw data in its native format on low-cost object storage.
Structured, semi-structured, and unstructured data coexist together — often before any transformation occurs.
Think of it as:
A massive warehouse where everything is stored first and organized later.
Cheap to scale. Expensive to manage poorly.
Core characteristics
- Schema-on-read
- Stores virtually any data type
- Extremely low-cost storage
- Decoupled compute and storage
- Historically weak transactional consistency (now addressable via open table formats layered on top)
Common implementations
- AWS S3 + Athena
- Google Cloud Storage + External Tables
- Azure Data Lake Storage Gen2
- MinIO (on-premises / hybrid)
Best suited for
- ML training datasets
- Raw telemetry and logs
- Image/video/audio storage
- Large-scale archival
- AI experimentation
The Data Lakehouse
The lakehouse is the architectural convergence of the warehouse and the data lake.
It adds:
- Transactional guarantees
- Governance
- Metadata management
- Query optimization
- Schema enforcement
…directly on top of object storage.
The key enabling technology behind this evolution is Apache Iceberg, which has emerged as the de facto open table format across the industry. Every major cloud platform — AWS, Azure, Google Cloud, Snowflake, and Databricks — now offers native Iceberg support.
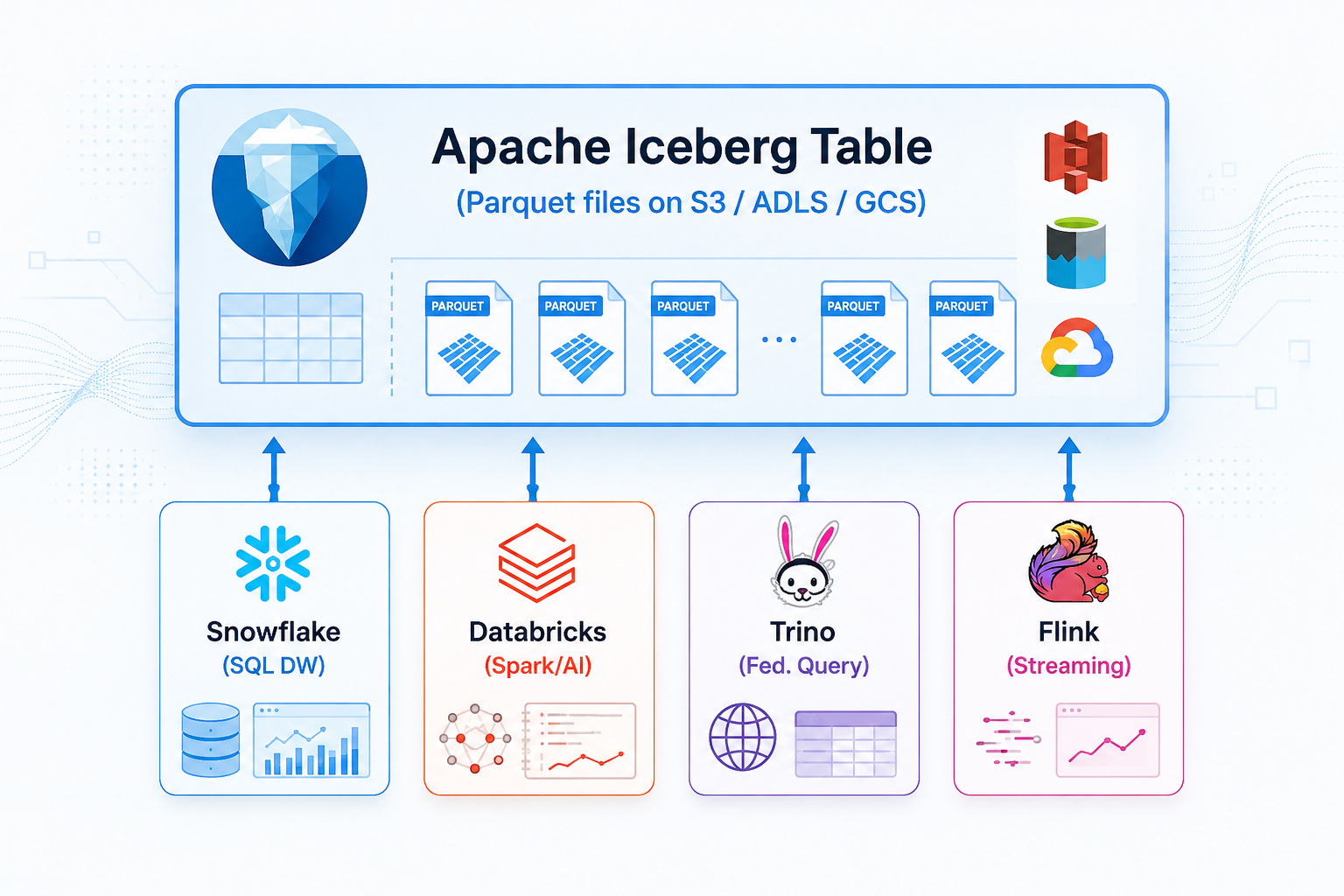
Apache Iceberg Architecture
Two other open table formats remain relevant in specific contexts:
- Delta Lake — dominant inside Databricks environments; interoperates with the broader Iceberg ecosystem via UniForm, which writes Delta tables that are simultaneously readable as Iceberg by external engines (Snowflake, BigQuery, Redshift, Athena, Trino, and others)
- Apache Hudi — strongest choice for streaming-heavy and CDC/upsert workloads, with mature record-level merge-on-read capabilities; now also offers native Iceberg-format output for interoperability
Think of it as:
A data lake that finally learned discipline.
Core characteristics
- ACID transactions on object storage
- Schema evolution
- Time travel and rollback
- Multi-engine interoperability (via Iceberg REST Catalog API)
- Decoupled compute architecture
Typical platforms
- Databricks (Delta Lake + UniForm for Iceberg interoperability; Unity Catalog)
- Snowflake (native Iceberg Tables + Snowflake Open Catalog, a managed Apache Polaris service)
- Google BigQuery (Lakehouse for Apache Iceberg — rebranded from BigLake in April 2026)
- Amazon Redshift + S3 Tables (the first cloud object store with built-in Iceberg support) + SageMaker Lakehouse
- Microsoft Fabric / OneLake (Delta-native with transparent Iceberg serving; GA interoperability with Snowflake)
- Cloudera (leading hybrid / on-prem open lakehouse; Iceberg REST Catalog + Cloudera AI Inference)
- Dremio (Iceberg-native lakehouse; co-creator of Apache Polaris)
- Starburst / Trino (federated lakehouse queries across engines)
Best suited for
- Mixed BI + AI workloads
- ML engineering
- AI-native applications
- Vendor-neutral platform strategies
- Long-term architectural flexibility
2. The Open Standards Layer — Where the Real Battle Is
In 2026, the architecture debate has shifted. The table format question is largely settled: Iceberg has won the interoperability layer. The active competitive frontier is now the catalog — the metadata brain that tells every engine where data lives, what it means, and who can access it.
Open Table Formats: The Current Landscape
| Format | 2026 Status | Strength |
|---|---|---|
| Apache Iceberg | De facto cross-engine standard. Native support across AWS, Azure, GCP, Snowflake, Databricks (via UniForm), Cloudera, Dremio, Starburst. Iceberg V3 in public preview (Databricks, Snowflake) with Deletion Vectors, Row Lineage, and VARIANT type. V4 under development with streaming-first improvements. | Multi-engine interoperability, partition evolution, hidden partitioning, time travel |
| Delta Lake | Dominant inside Databricks. Outside Databricks, the path to interoperability is UniForm — write once as Delta, read as Iceberg from any engine. Iceberg V3 adoption of features like Deletion Vectors further narrows the gap. | Photon engine optimization, deep Databricks integration, mature Spark ecosystem |
| Apache Hudi | Niche but not declining. Strongest for streaming / CDC / record-level upsert workloads. Now offers native Iceberg-format output. Positioned as a "Data Lakehouse Management System" (DLMS). | Merge-on-read, record-level CDC, near-real-time ingestion |
Open Catalogs: The New Battleground
The catalog is the metadata layer that makes multi-engine lakehouse architectures work. It registers tables, enforces access control, tracks schema evolution, and exposes data to query engines. The Iceberg REST Catalog API has become the de facto interoperability standard — nearly every major catalog implements it.
| Catalog | Backed By | Key Differentiator |
|---|---|---|
| Apache Polaris | Co-created by Snowflake and Dremio; donated to ASF in August 2024; graduated to top-level Apache project in February 2026 | Vendor-neutral, open-source, Iceberg REST Catalog native |
| Snowflake Open Catalog | Snowflake (managed Apache Polaris) | Fully managed; GA with billing beginning H1 2026 |
| Unity Catalog (OSS) | Databricks (open-sourced under Apache 2.0 at Data + AI Summit 2024) | Multi-format (Delta, Iceberg, Hudi via UniForm); integrated AI/BI governance |
| AWS Glue Data Catalog | AWS | Deep AWS integration; Iceberg REST Catalog adapter available |
| Lakehouse Runtime Catalog | Google Cloud (rebranded from BigLake metastore, April 2026) | Native BigQuery integration; cross-cloud federation in preview |
| Apache Gravitino | Datastrato (open-sourced) | "Catalog of catalogs" — federates across Hive, Iceberg, Paimon catalogs |
| Dremio Arctic / Nessie | Dremio | Git-like catalog versioning; Iceberg-native |
No single catalog dominates. A January 2026 practitioner survey showed fragmented adoption: AWS Glue (39%), Nessie (29%), S3 Tables (25%), Polaris (21%), and Hive Metastore (18%) — reflecting an ecosystem in rapid transition.
The strategic takeaway: When evaluating a data platform in 2026, the catalog choice matters as much as the compute engine. Ask: Does this catalog implement the Iceberg REST API? Can I federate it with catalogs from other vendors? Can AI agents discover and access data through it programmatically?
3. AI-Ready Data Architecture — What Your Platform Must Support
The article's opening premise — that architecture choices should be driven by AI readiness — demands specifics. Here are the seven capabilities that define an AI-ready data platform in 2026.
3.1 AI Agents as First-Class Data Consumers
Data platforms are no longer built exclusively for human analysts writing SQL. In 2026, AI agents — from Snowflake Cortex Intelligence to Databricks AI/BI Genie to autonomous LLM-powered workflows — are becoming primary consumers of enterprise data.
This changes what "data access" means:
- Machine-readable metadata becomes as important as human-readable documentation
- Context engineering — providing agents with the right schema, lineage, and business glossary context — replaces ad-hoc prompt construction
- Fine-grained access control must extend to agent identities, not just human users
- Catalog discoverability (via Iceberg REST API) enables agents to find and query data without hardcoded table references
3.2 Native Vector and Hybrid Search
A separate vector database is no longer mandatory for most production AI patterns. Every major platform now offers native vector capabilities:
- Snowflake Cortex (vector search + embedding functions)
- Databricks (vector search index on Unity Catalog)
- BigQuery (vector search with embeddings)
- Amazon Redshift + Bedrock (vector similarity via integration)
- ClickHouse, DuckDB/MotherDuck (native vector extensions)
The emerging standard is hybrid search — combining traditional keyword (lexical) search with vector (semantic) search in a single query. Mature platforms support this natively, eliminating the need to synchronize data between a warehouse and a standalone vector store.
3.3 Semantic Layers for LLMs
AI models produce better results when they understand not just raw table schemas, but business meaning — what a metric represents, how dimensions relate, and what calculations are canonical.
The most important development here is the Open Semantic Interchange (OSI) initiative, launched on September 23, 2025, by a coalition of 16 organizations including Snowflake, Salesforce, dbt Labs, BlackRock, RelationalAI, Alation, Atlan, Mistral AI, ThoughtSpot, Hex, Sigma, and others. OSI aims to create a common semantic standard that allows AI models to consume business context consistently across platforms.
dbt Labs has open-sourced MetricFlow under Apache 2.0 as the initial reference implementation. Databricks SQL has also shipped its own semantic layer capabilities.
Why this matters for architecture decisions: A platform that supports a semantic layer — or at minimum exposes metric definitions and business glossaries via APIs — will produce dramatically better results from AI agents and LLM-powered analytics than one that exposes only raw tables.
3.4 Data Products, Contracts, and Mesh
Data mesh — the organizational pattern of decentralized, domain-owned data with federated governance — has moved from hype to mainstream in 2026.
The practical manifestations that matter for architecture selection:
- Data products — self-describing, versioned, SLA-backed datasets published by domain teams for cross-team consumption
- Data contracts — schema and quality guarantees enforced at ingestion boundaries, preventing breaking changes from propagating downstream
- Data quality dashboards and SLO/SLA tracking — now standard in platforms like Monte Carlo, Alation, and native Databricks/Snowflake observability features
These are no longer future-state aspirations. They are table-stakes hygiene for any organization building AI pipelines on top of enterprise data.
3.5 Streaming-First Lakehouse Ingestion
Batch-only ingestion is insufficient for AI workloads that require near-real-time feature stores, live dashboards, or event-driven agent triggers.
The streaming-to-Iceberg pipeline has become a default pattern:
- Confluent Tableflow — Kafka topics materialized directly as Iceberg tables
- Snowpipe Streaming — sub-second ingestion into Snowflake Iceberg tables
- RisingWave, Apache Flink — streaming SQL engines writing directly to Iceberg
- StreamNative Ursa — Pulsar-to-Iceberg bridge
Iceberg V4, currently under development, is being designed explicitly to improve streaming support with faster commit cycles and append-optimized metadata handling.
3.6 Open Observability and Governance Standards
AI-ready architectures require lineage, quality, and cost visibility across every layer:
- OpenLineage — open standard for data lineage collection across heterogeneous pipelines
- OpenTelemetry GenAI conventions — emerging standard for tracing AI/LLM workloads end to end
- FOCUS — FinOps open standard for normalizing cloud cost data (see Section 4 below)
- Iceberg REST Catalog API — the interoperability backbone connecting all of the above
3.7 The AI Readiness Checklist
When evaluating any data platform in 2026, ask:
| Capability | Question to Ask |
|---|---|
| Open table format | Does it store data in Apache Iceberg (or interoperate via UniForm)? |
| Open catalog | Does it expose an Iceberg REST Catalog API for multi-engine access? |
| Vector + hybrid search | Can I run semantic search alongside SQL without a separate vector database? |
| Semantic layer | Does it support OSI, MetricFlow, or a native semantic/metrics layer? |
| Data products | Can domain teams publish versioned, SLA-backed data products? |
| Streaming ingestion | Can I ingest streaming data directly into Iceberg tables? |
| Cost transparency | Does it provide FOCUS-compliant billing data for FinOps? |
4. FinOps for Data Platforms — The Cost Conversation You Cannot Skip
Data platform costs are one of the fastest-growing line items in enterprise IT budgets — and one of the hardest to govern. Each vendor uses proprietary consumption units (Snowflake credits, Databricks DBUs, BigQuery slots, Redshift RPUs) that make cross-platform cost comparison nearly impossible without standardization.
The FOCUS Standard
The FinOps Foundation has formally extended its scope to cover data cloud platforms, recognizing this gap. The FOCUS (FinOps Open Cost and Usage Specification) is the emerging open standard for normalizing billing data across clouds and SaaS platforms.
- FOCUS 1.3 was ratified on December 5, 2025
- Databricks already provides FOCUS-formatted billing data (private preview)
- Snowflake has committed to FOCUS support in 2026
- AWS, Azure, and Google Cloud all support FOCUS for their core infrastructure billing
What This Means for Architecture Decisions
Cost governance should be a first-class architecture requirement, not an afterthought. When evaluating platforms:
- Demand query-level cost attribution — who ran what, and what did it cost?
- Monitor commitment utilization — are your reserved capacity contracts actually being consumed?
- Separate storage vs. compute cost trends — lakehouse architectures decouple these, but only if you track them independently
- Use FOCUS-compliant data to normalize costs across platforms in multi-engine environments
The scale of spend involved is significant. For reference, Snowflake reported full-year FY2026 product revenue of $4.47 billion (29% YoY growth); Databricks reported crossing a $5.4 billion revenue run-rate with over 65% year-over-year growth. These numbers represent real enterprise data platform budgets — and real opportunities for optimization.
Final Thought: This Is No Longer a Storage Decision
The warehouse-vs-lake debate is now obsolete.
The real architecture question in 2026 is:
How quickly can your platform evolve alongside AI?
Your decisions around:
- Open table formats (Iceberg as the default interoperability layer)
- Open catalogs (Polaris, Unity Catalog, Gravitino — and the Iceberg REST API that connects them)
- Semantic modeling (OSI, MetricFlow, and platform-native semantic layers)
- AI-agent access patterns (machine-readable metadata, vector search, context engineering)
- Compute flexibility (multi-engine architectures sharing the same Iceberg tables)
- Cost governance (FOCUS-compliant billing, query-level attribution)
…will directly determine:
- how effectively AI agents can access your data,
- how fast ML teams can iterate,
- how expensive future platform migrations become,
- and how much you spend getting there.
The enterprises winning the next decade are not choosing a single "best" platform.
They are building adaptable, open-standards-based architectures designed for continuous change — where data is stored once in Iceberg, governed through an open catalog, and queried by whatever engine (or agent) delivers the best result for each workload.
About DataMy
DataMy is a Singapore-based data and AI consulting firm helping enterprises across APAC modernize their analytics, AI, and governance architecture.
Services
- Data platform architecture assessments
- Lakehouse modernization strategy
- Apache Iceberg adoption and open catalog advisory
- AI readiness evaluation and agent-ready data design
- Semantic layer implementation (OSI, MetricFlow, dbt)
- Open catalog strategy (Apache Polaris, Unity Catalog, Gravitino)
- Data platform FinOps and cost optimization
- Governance, data contracts, and residency advisory
Expertise across
- Snowflake
- Databricks
- Microsoft Fabric
- Cloudera
- Google BigQuery
- Dremio
- dbt Labs
- Denodo
For inquiries: [email protected]