The Smarter the Agent, the Worse the Last-Mile Problem
Enterprise AI investment is accelerating. Across large organizations in financial services, manufacturing, and professional services, AI agent pilot programs have moved from a fringe experiment to a standard item on the technology roadmap. The models powering those agents — Claude, GPT-4o, Gemini — are genuinely impressive. They can reason, plan multi-step workflows, and write executable code on demand.
And yet the most common complaint from the teams deploying them is not about model quality. It is about reach.
An agent that cannot read your CRM pipeline data cannot tell you which deal is at risk. An agent that cannot write to your ticketing system cannot actually close a support ticket. An agent that cannot query your data warehouse cannot answer "what was our Q1 margin by segment?" with real numbers. No matter how capable the underlying model, an agent isolated from the business systems that hold the data is fundamentally limited to tasks that fit inside a chat window.
This is the last-mile problem of enterprise AI — and it is the problem that the Model Context Protocol (MCP) was designed to solve.
What MCP Is — and What It Is Not
MCP is an open standard, originally developed by Anthropic and released in November 2024, that defines how AI models communicate with external tools, databases, and services. On December 9, 2025, Anthropic donated MCP to the Agentic AI Foundation (AAIF), a directed fund under the Linux Foundation co-founded with Block and OpenAI — formalizing it as a vendor-neutral, community-governed standard rather than a proprietary Anthropic protocol. By mid-2026, Claude, ChatGPT, Gemini, Microsoft Copilot, Cursor, and VS Code have all shipped native MCP support. The Python and TypeScript SDKs combined recorded over 97 million monthly downloads as of March 2026 — a growth rate that mirrors the adoption curves of foundational infrastructure protocols like REST APIs in their early years.
The frequently used analogy — MCP as the "USB-C for AI" — is accurate in a specific way. Before USB-C, every peripheral required its own cable and driver. Before MCP, every AI tool connecting to every data source required custom integration code: parse the model's function-calling format, authenticate with the target system, translate between schemas, handle errors, repeat. Multiply by the number of AI tools times the number of enterprise systems, and the integration surface became unmaintainable within months. MCP standardizes the interface on both sides.
What MCP is not: it is not a replacement for your data infrastructure. It is not an ETL pipeline. It does not move or store data. It is a communication protocol — a standardized contract that lets an agent discover what capabilities a system exposes, call those capabilities safely, and receive structured results.
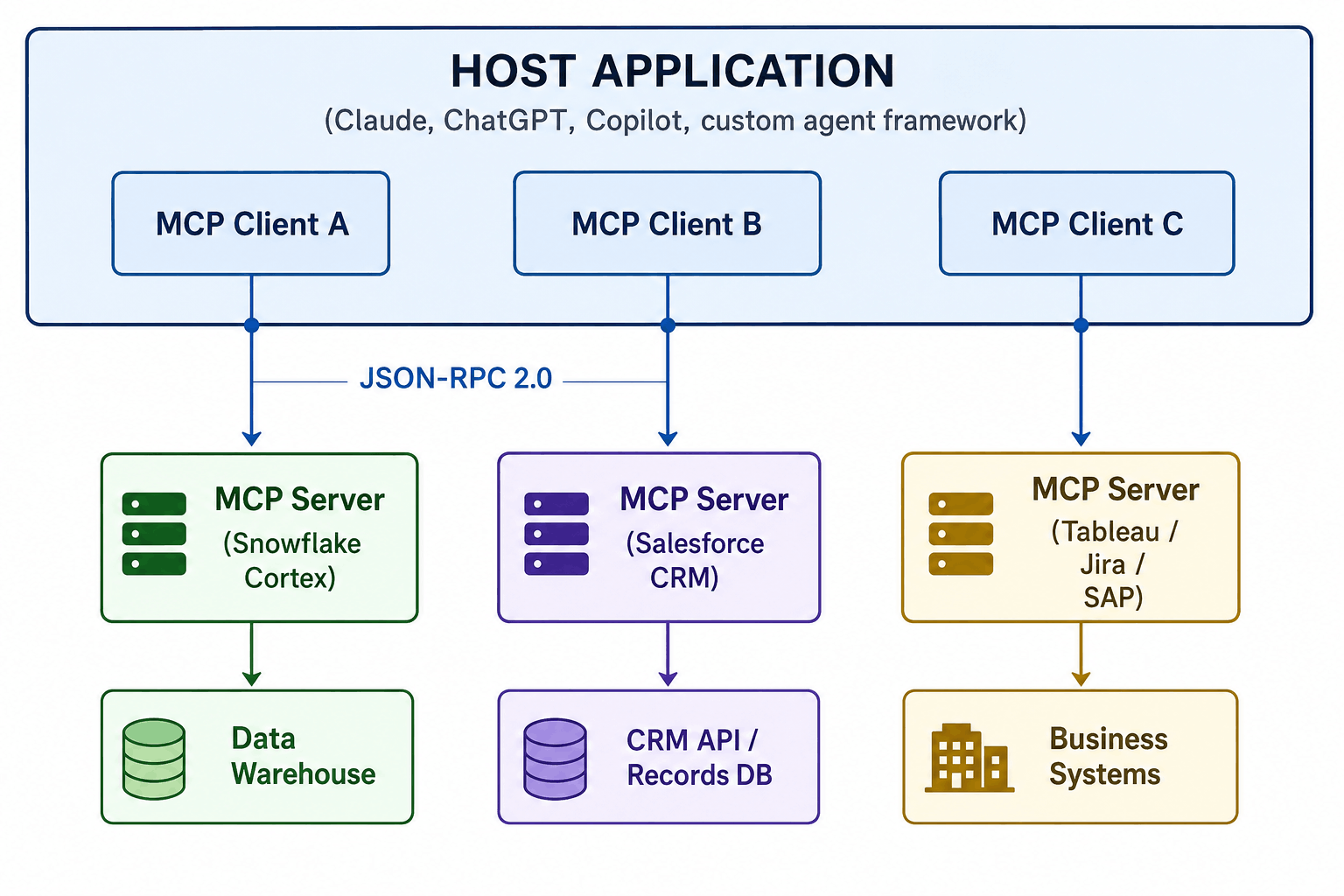
The Architecture in Three Parts
Understanding why MCP works at enterprise scale requires looking at its three-component architecture.
MCP client-server connection
The Host is the AI application — the platform that contains the model and orchestrates conversations or agentic workflows. Claude Managed Agents, Claude Desktop, a custom Python agent built with the Anthropic SDK — all are hosts.
The MCP Client lives inside the host and handles the protocol conversation: connection negotiation, tool discovery, tool calls, and result handling. Each client maintains a one-to-one connection with one MCP server.
The MCP Server is the bridge to a real system. It exposes the capabilities of that system as a defined set of tools (executable actions), resources (readable data), and prompts (templated instructions). The server handles authentication with the underlying system and executes tool calls on the agent's behalf.
Communication runs over JSON-RPC 2.0. For local tools (a script running on the same machine), transport is stdio — the server is a subprocess. For remote enterprise systems, transport is HTTP with Server-Sent Events and mandatory OAuth 2.1 authentication, as defined in the March 2026 MCP specification update.
When an agent needs to act, the flow is:
- Agent sends a
tools/listrequest — the MCP server responds with a schema of everything it can do - Agent selects a tool and sends
tools/callwith parameters - MCP server validates inputs, calls the underlying API or database
- Result returns to the agent as structured JSON
- Agent incorporates the result into its reasoning and continues
The agent never directly touches the underlying system's API. The MCP server is the gatekeeper — and that matters enormously for enterprise security.
Why This Changes Enterprise AI Deployments
From Isolated Chatbot to Workflow Actor
Without MCP, most enterprise AI deployments follow the same pattern: an employee pastes data into a chat window, the model analyzes it, the employee pastes the result into a downstream system. The agent is a highly intelligent clipboard.
With MCP, the agent holds authenticated sessions to the systems it needs. It can query a CRM, pull a deal status, cross-reference it with financial data in a warehouse, generate a summary, and open a ticket — in a single automated workflow, with every step logged. The difference is not incremental; it is architectural.
A concrete example from a field engagement: before MCP, a data analyst asking Claude to help with a quarterly sales review had to export a CSV from Snowflake, upload it to Claude, describe the schema manually, and then manually paste any findings back into their reporting tool. With a Snowflake MCP server configured, the analyst says: "Compare Q1 and Q2 product margin by region — highlight any region where margin fell more than 5 points." Claude issues a tools/call, the MCP server executes the SQL query against Snowflake, returns the result, and Claude generates the analysis directly. Zero file handling. Zero schema description. The analyst's job is to interpret and act, not to move data.
The Tool Discovery Advantage
One of MCP's underappreciated properties is dynamic tool discovery. The agent does not need to be programmed with the exact schema of each connected system at build time. It issues a tools/list at runtime and gets the current capability set — which means MCP servers can add new tools, update schemas, or change capabilities without requiring changes to the agent.
To make this concrete: an enterprise data MCP server might expose half a dozen distinct tools. Here is a simplified example of how that server definition looks in practice, using the MCP Python SDK:
# enterprise_data_mcp_server.py from mcp.server import Server from mcp.server.stdio import stdio_server from mcp import types server = Server("enterprise-data-server") @server.list_tools() async def list_tools() -> list[types.Tool]: return [ types.Tool( name="query_sales_data", description="Query sales records from the data warehouse by region, product, or date range.", inputSchema={ "type": "object", "properties": { "region": {"type": "string", "description": "e.g. APAC, EMEA, Americas"}, "start_date": {"type": "string", "description": "ISO 8601 format"}, "end_date": {"type": "string", "description": "ISO 8601 format"}, "metric": {"type": "string", "enum": ["revenue", "margin", "units"]}, }, "required": ["metric"], }, ), types.Tool( name="get_crm_pipeline", description="Return open opportunities from Salesforce CRM filtered by stage or owner.", inputSchema={ "type": "object", "properties": { "stage": {"type": "string", "enum": ["Prospecting", "Proposal", "Negotiation", "Closed Won"]}, "owner_email": {"type": "string"}, }, }, ), types.Tool( name="create_jira_ticket", description="Open a Jira issue in the specified project with a given summary and description.", inputSchema={ "type": "object", "properties": { "project_key": {"type": "string"}, "summary": {"type": "string"}, "description": {"type": "string"}, "priority": {"type": "string", "enum": ["Low", "Medium", "High", "Critical"]}, }, "required": ["project_key", "summary"], }, ), ] @server.call_tool() async def call_tool(name: str, arguments: dict): if name == "query_sales_data": return await run_warehouse_query(arguments) elif name == "get_crm_pipeline": return await fetch_salesforce_pipeline(arguments) elif name == "create_jira_ticket": return await post_jira_issue(arguments) else: raise ValueError(f"Unknown tool: {name}") if __name__ == "__main__": import asyncio asyncio.run(stdio_server(server))
When the agent connects to this server, the first thing it does is call tools/list. The server returns all three tool schemas — names, descriptions, and input shapes — as a JSON-RPC response:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"tools": [
{ "name": "query_sales_data", "description": "Query sales records...", "inputSchema": { ... } },
{ "name": "get_crm_pipeline", "description": "Return open opportunities...", "inputSchema": { ... } },
{ "name": "create_jira_ticket", "description": "Open a Jira issue...", "inputSchema": { ... } }
]
}
}
The agent reads these schemas and decides which tool to invoke based on the user's intent. When it calls query_sales_data, the routing is explicit in the tools/call request body:
{
"jsonrpc": "2.0",
"id": 2,
"method": "tools/call",
"params": {
"name": "query_sales_data",
"arguments": {
"region": "APAC",
"start_date": "2026-01-01",
"end_date": "2026-03-31",
"metric": "margin"
}
}
}
The call_tool dispatcher in the server routes by name — query_sales_data goes to the warehouse, get_crm_pipeline goes to Salesforce, create_jira_ticket goes to Jira. Each underlying system's credentials and connection logic live inside the server; the agent sees only the tool name and the structured result that comes back. This is the key point: the agent reasons at the level of "what capability do I need," not "how do I authenticate with Salesforce's REST API."
For enterprise environments where APIs evolve and systems are regularly updated, this is significant. A new tool added to the server — say, a get_hr_org_chart capability — becomes available to every connected agent on the next tools/list call, with no agent redeployment required.
Governance Is Built Into the Protocol
The MCP server pattern creates a natural governance layer — not by accident, but because of how the protocol forces all access to flow through a single, controlled boundary. Here is what that layer concretely contains.
Credential isolation. The agent never receives, stores, or transmits the credentials that connect to the underlying system. Those secrets — database passwords, API keys, OAuth tokens for Salesforce or Jira — live only inside the MCP server process, managed by the server operator. From the agent's perspective, there are only tool names and input parameters. This is structurally different from a direct API integration, where the agent (or the application orchestrating it) must hold credentials to every system it touches.
Tool-surface as access policy. The set of tools a server exposes is itself a governance decision. A query_sales_data tool that only accepts aggregated queries and never returns raw customer records enforces a data access policy at the schema level — regardless of what the agent asks for. An analyst-facing server might expose read-only query tools; an operations-facing server on the same underlying system might additionally expose write tools. The server operator defines the surface; the agent operates within it and cannot exceed it.
Identity-aware routing and per-caller authorization. Production MCP servers receive the identity of the calling agent or user through the authentication handshake (OAuth 2.1 for remote servers, per the March 2026 MCP specification). The server can enforce per-identity tool-level authorization: an agent acting on behalf of a junior analyst can be blocked from calling export_full_dataset even though the tool exists on the same server that senior analysts access freely. This is the equivalent of RBAC at the tool layer — finer-grained than the platform-level role, because it applies to individual callable actions rather than broad read/write permissions.
Input validation before execution. Every tool defines a JSON Schema for its inputSchema. Before the server executes any tool call, the inputs are validated against that schema — type checking, enum constraints, required fields. A query_sales_data tool that enumerates "metric": ["revenue", "margin", "units"] will reject any call that tries to pass an arbitrary SQL string. Prompt injection attempts — where a malicious input tries to manipulate the server into executing unintended actions — are constrained by this validation boundary.
Immutable audit trail. Each tools/call is a discrete, structured, loggable event: which agent called which tool, with what parameters, at what time, and what result was returned. Because every action flows through the MCP server, audit logging can be applied centrally at one layer rather than instrumented separately across every downstream system. This is the property that makes agent activity auditable in the same way that a database query log or an API gateway access log is auditable — a complete record that can be ingested into a SIEM or governance dashboard without agent-specific instrumentation.
Rate limiting and resource guardrails. The MCP server sits between the agent and the underlying resource, which means it is also the natural place to enforce usage controls: maximum rows returned per call, maximum calls per minute per agent identity, query complexity limits on warehouse tools. Without this layer, a runaway agent loop issuing thousands of warehouse queries would hit the database directly. With it, the server can throttle, queue, or reject calls before they reach the system.
Taken together, these properties mean that MCP does not simply connect agents to enterprise systems — it connects them in a way that preserves the auditability, access control, and least-privilege principles that enterprise security and compliance teams require. The governance conversation for agent deployments moves from "how do we prevent the agent from accessing things it shouldn't" to "what surface do we deliberately expose on the MCP server" — a much more tractable design problem.
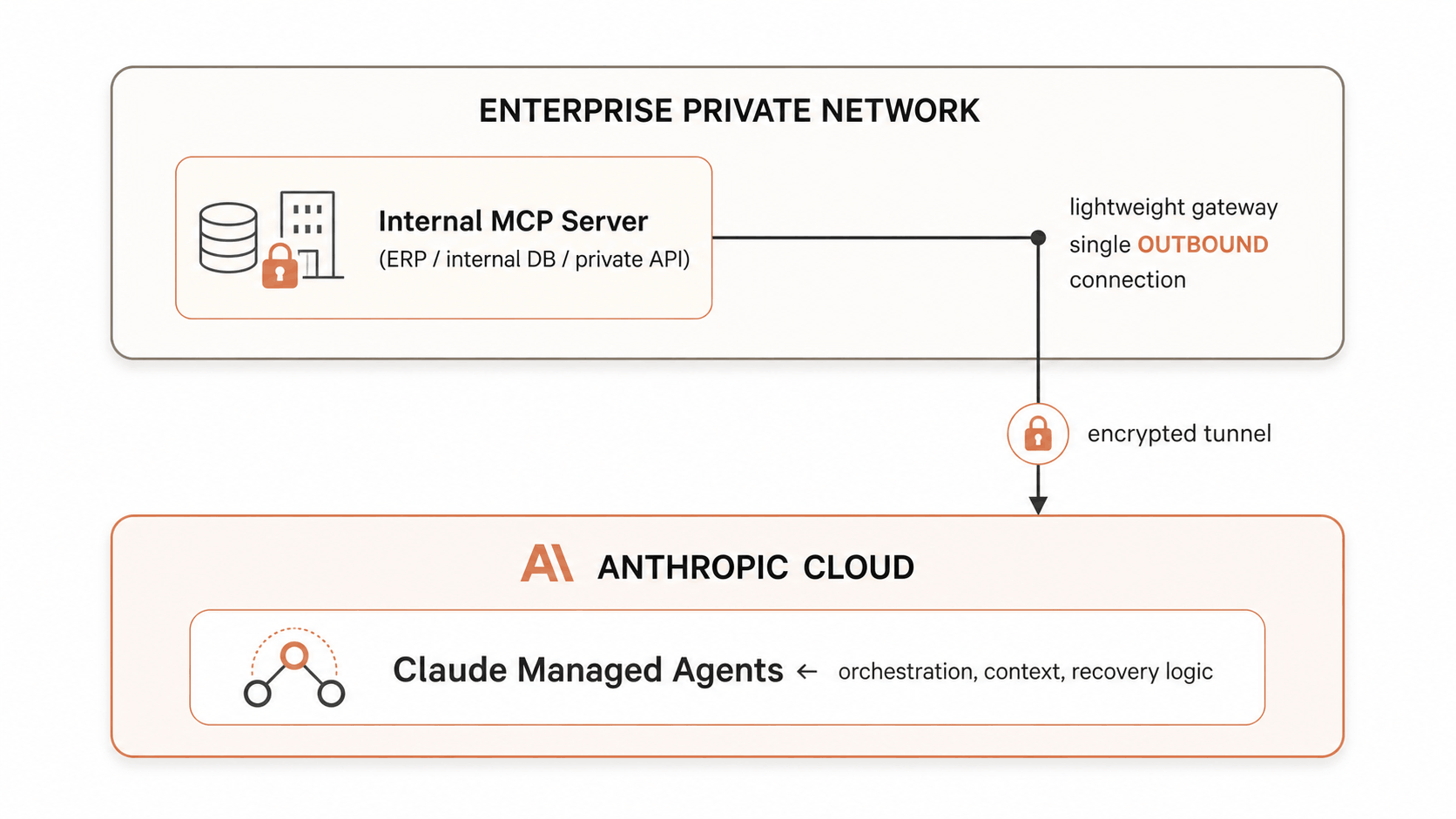
MCP Tunnels: The Breakthrough for Private Enterprise Networks
The most significant recent development is the announcement of MCP tunnels in Claude Managed Agents, unveiled at Code with Claude London on May 19, 2026, with self-hosted sandboxes entering public beta and MCP tunnels entering research preview simultaneously.
The problem MCP tunnels solve is fundamental: most enterprise data does not live in public-internet-accessible services. It lives behind firewalls, in private VPCs, on on-premises infrastructure, in systems that IT policy explicitly prohibits from having inbound connections from external services. For any AI agent hosted in the cloud — including Claude Managed Agents — connecting to these systems previously required either punching holes in the firewall (unacceptable to most security teams) or building complex VPN infrastructure.
MCP tunnels and network
MCP tunnels invert this model:The internal MCP server makes a single outbound connection to the tunnel endpoint. No inbound firewall rules. No public endpoints. Traffic is encrypted end-to-end. The agent in the cloud can call tools on the internal MCP server exactly as it would call any other MCP server — from the agent's perspective, there is no difference.
This architecture means an enterprise can expose its internal ERP, internal databases, private REST APIs, and knowledge bases to a Claude agent without those systems ever being reachable from the public internet. The security perimeter remains intact.
Combined with self-hosted sandboxes (also released in May 2026), where tool execution runs on customer-controlled infrastructure rather than Anthropic's shared environment, organizations now have a complete architecture where:
- Model intelligence lives in the cloud
- Data and tool execution stay inside the security boundary
- No sensitive data needs to leave the enterprise environment
Enterprise MCP Adoption: Where the Market Stands
As of mid-2026, the MCP server ecosystem spans multiple public registries: mcp.so lists over 20,000 servers, Smithery catalogs more than 7,000, and the official MCP Registry (backed by Anthropic, GitHub, and Microsoft) provides a curated subset of verified entries. Enterprise platform adoption has accelerated significantly since Q1 2026.
Snowflake has moved furthest on the data platform side. Snowflake's managed MCP servers allow Cortex Agents to connect to Salesforce, Google Workspace, Jira, Slack, and other enterprise tools directly via MCP. The Natoma acquisition (announced alongside Q1 FY2027 earnings) specifically targets governance and identity controls for agents accessing enterprise systems through MCP. Snowflake Intelligence — Snowflake's emerging agentic control layer — uses MCP connectors as the integration backbone.
Salesforce has MCP gateways in production for CRM data access — agents can query pipeline, update records, and trigger workflows through a governed MCP interface.
Microsoft has published MCP server support in Azure API Management, with explicit documentation on how enterprise APIs can be exposed as MCP-compatible endpoints with existing APIM authentication policies applied.
Tableau MCP (in production since early 2026) allows AI agents to list workbooks, query datasources, pull view data, and render visualizations — directly from a natural language interface without any user clicking or exporting.
According to Stacklok's 2026 software survey, approximately 41% of software organizations now have MCP servers in limited or broad production — a significant shift from the experimental phase of late 2024, when MCP was largely confined to developer tooling and local-machine integrations.
What Enterprise Data Teams Need to Do Now
MCP does not eliminate the need for strong data foundations — it amplifies whatever foundation you have. An agent with MCP access to an ungoverned data warehouse will confidently surface incorrect numbers faster than ever. The protocol is the pipe; the quality of what flows through it still depends on your data engineering.
Four actions for data teams:
1. Inventory which systems are MCP-ready
Check whether your key enterprise systems have published MCP servers: data warehouse, CRM, ERP, BI platform, ticketing system, HR system. Many have official servers now; others have community-maintained ones. Start with what exists.
2. Define the governance model before the first production deployment
The MCP server is where you enforce data access policies for agents. Decide: which agent identities get access to which tools? What logging is required on tool calls? Are there schemas or tables that agents should never reach? These decisions are architecturally equivalent to RBAC on your data platform — and need the same rigor.
3. Build your semantic layer before your agent layer
The agents that hallucinate or give wrong answers in production are almost always accessing raw tables without a semantic layer. If "revenue" means different things in three systems, an agent querying all three will blend them incorrectly and sound authoritative doing it. Governed metric definitions — whether through dbt MetricFlow, Snowflake Semantic Views, or Databricks AI/BI Genie — are the prerequisite for trustworthy agent outputs.
4. Evaluate MCP tunnels for on-premises or restricted systems
If your most critical data assets are behind firewalls — SAP on-premises, legacy databases, internal APIs — MCP tunnels are now a production-grade architecture for exposing them to cloud agents without compromising security posture. The research preview status of Claude's MCP tunnel implementation means piloting now is prudent; production-readiness is expected in H2 2026.
The Shift in What "AI Integration" Means
For the past two years, the dominant enterprise AI question was about the model: which LLM, which fine-tuning approach, which prompt engineering technique? The assumption was that the model was the hard part.
That assumption is being displaced. The model quality problem is largely solved — state-of-the-art models in 2026 are broadly capable for enterprise task types. The hard problem, as it turns out, is reach. Getting the agent to the data it needs, in a way that respects governance, passes security review, and is maintainable as systems evolve.
MCP is the architectural answer to the reach problem. Not because it is magic, but because it creates the standardized infrastructure layer that was missing — the layer that lets an agent treat an enterprise data warehouse, a CRM, an ERP, and a ticketing system as first-class tools rather than black boxes that require custom integration work for every new connection.
The organizations building on this architecture now — wiring their governed data platforms to MCP servers, defining access policies at the protocol layer, piloting MCP tunnels for private systems — are the ones whose AI agents will actually do work by the end of 2026. The others will still be exporting CSVs.
Work With DataMy: Building Your MCP-Ready Data Architecture
DataMy works with organizations across APAC on the full stack of enterprise data integration — from platform selection and governance frameworks to AI agent deployment. If you are evaluating how to make your data infrastructure agent-accessible:
- MCP Readiness Assessment — we audit your current data platform and enterprise systems against the MCP connector landscape, identify what is production-ready today and what needs preparatory work, and deliver a phased integration roadmap
- Semantic Layer Design — we build the governed metric and dimension definitions that make agent-generated outputs trustworthy: dbt MetricFlow, Snowflake Semantic Views, or Databricks AI/BI Genie depending on your stack
- Agent + MCP Pilot — end-to-end pilot connecting a Claude or other LLM-based agent to your data platform via MCP, with governance controls, audit logging, and an evaluation framework to measure accuracy and business value
- MCP Tunnel Architecture for Private Systems — for organizations with on-premises or firewall-restricted data systems, we design and implement the tunnel architecture that enables cloud agents to reach internal systems without compromising your security perimeter
Contact us: [email protected] Website: datamy.co
References
- Introducing the Model Context Protocol — Anthropic
- Donating MCP and Establishing the Agentic AI Foundation — Anthropic
- Linux Foundation Announces Formation of the AAIF — Linux Foundation Press Release, December 9, 2025
- MCP Joins the Agentic AI Foundation — MCP Blog, December 9, 2025
- New in Claude Managed Agents: Self-Hosted Sandboxes and MCP Tunnels — Claude Blog
- Anthropic Enhances Claude Managed Agents — 9to5Mac, May 19, 2026
- MCP Hits 97M Downloads — Digital Applied
- Official MCP Registry — modelcontextprotocol.io
- Best MCP Registries in 2026 — TrueFoundry
- Anthropic Introduces MCP Tunnels for Private Agent Access to Internal Systems — InfoQ
- Claude Agents Can Finally Connect to Enterprise APIs Without Leaking Credentials — VentureBeat
- Introducing Snowflake Managed MCP Servers for Secure, Governed Data Agents — Snowflake Blog
- Snowflake to Acquire MCP-Focused Natoma to Boost Governance for AI Agents — CIO
- Enterprise MCP Architecture Patterns for Data Integration — CData
- The Definitive 2026 Guide to Implementing MCP in Enterprise Environments — CData / Medium
- Model Context Protocol (MCP) 2026 Roadmap: Scalability, Enterprise Auth, and Governance — CallSphere
- MCP Roadmap 2026 — Official Priorities for Model Context Protocol — AAIF / a2a-mcp.org
- Overview of MCP Servers in Azure API Management — Microsoft Learn
- Model Context Protocol — Wikipedia