"Your BI-first platform won't survive 2026—but your data tools might"
Most mid-market APAC enterprises built their data platforms around a simple formula: a data warehouse, some ETL pipelines, and a BI tool. By 2026, that architecture fails on three dimensions that matter.
It's not AI-ready. It's batch-only when operational decisions increasingly need real-time signals. And its governance exists on paper—the MAS Data Governance Guidelines (2024) require technical enforcement built into your architecture, not policies in a folder.
Here's the twist: the data tools themselves have moved on. Modern BI and analytics platforms now deliver proactive AI-powered alerts, conversational data exploration, and agentic workflows — without anyone opening a dashboard. The tools aren't the problem. The foundation beneath them is.
The 2026 upgrade path is simple to state: fix the platform below your tools, then let their AI capabilities compound on a solid foundation.
This article walks through the six essential layers every modern data platform needs, the regulatory context for Singapore and APAC, and a practical checklist for assessing where your architecture stands today.
1. The Architecture Has Shifted: From Stack to Platform
The modern data platform is no longer a single product — it is a coordinated set of cloud-native layers managing the entire data lifecycle from ingestion through AI consumption. The term "modern data stack" has evolved into "modern data platform" because expectations now extend beyond analytics into AI readiness, real-time pipelines, and governed self-service access.
By 2026, organizations are consolidating around data lakehouse architectures, which merge the flexible low-cost storage of a data lake with the governance and query performance of a data warehouse. The warehouse-or-lake binary choice is largely over.
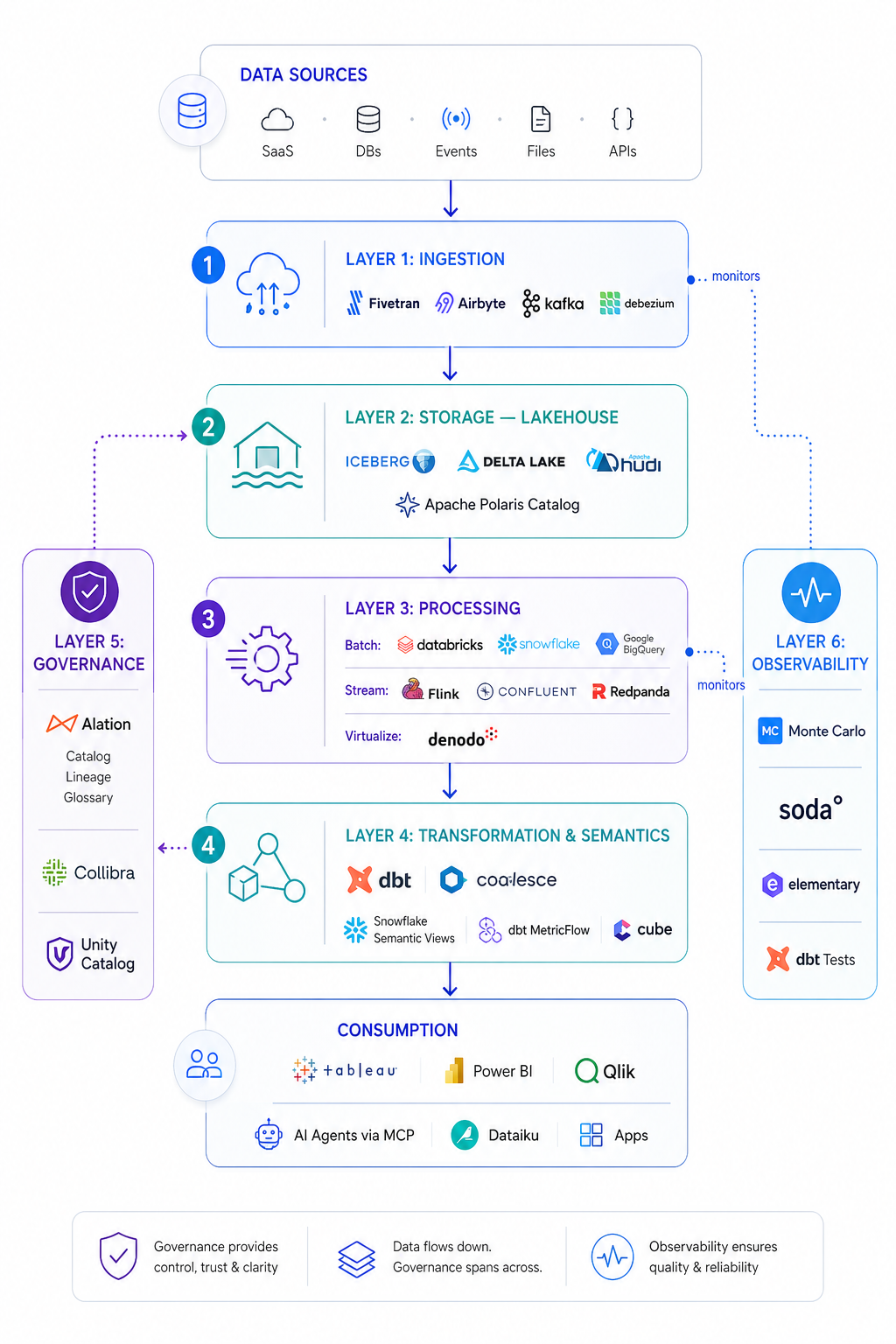
The Six-Layer Modern Data Platform Stack
2. The Six Core Layers
These layers are not optional — each addresses a specific failure point in traditional architectures.
Layer 1: Ingestion
The ingestion layer handles data arriving from SaaS tools, APIs, flat files, event streams, databases, and IoT devices. By 2026, leading architectures support batch, micro-batch, and real-time streaming simultaneously.
Change Data Capture (CDC) is particularly important — Debezium paired with Apache Kafka is the dominant open-source pattern for capturing only row-level changes rather than reloading full datasets.
Managed ELT connector tools — such as Fivetran (enterprise-managed connectors) and Airbyte (open-source self-hosted) — are how data practically arrives from source systems in the majority of modern stacks. Both output directly to cloud warehouses and lakehouses.
Layer 2: Storage — The Lakehouse as Default
Open table formats — Apache Iceberg, Delta Lake, and Apache Hudi — layer ACID transactions, schema evolution, and time travel on top of object storage, making them the foundational technology of the modern lakehouse.
| Table Format | Best For | Ecosystem |
|---|---|---|
| Apache Iceberg | Multi-engine, vendor-neutral architectures | Universal — all major clouds support it natively |
| Delta Lake | Databricks-centric / Spark-heavy stacks | Tight Databricks integration; converging on Iceberg compatibility |
| Apache Hudi | Streaming-heavy, upsert-intensive workloads | Primarily AWS/cloud-native streaming environments |
Databricks' 2024 acquisition of Tabular — co-founded by the original Iceberg creators at Netflix — signals accelerating convergence on Iceberg as the interoperability standard. Apache Polaris Catalog (incubating at ASF since 2024, open-sourced by Snowflake) provides a vendor-neutral catalog layer enabling Databricks, Snowflake, Trino, Flink, and others to read and write the same Iceberg tables via a standardized REST API.
Layer 3: Processing — Batch, Streaming, or Both
| Mode | Recommended For |
|---|---|
| Streaming | Fraud detection, real-time personalization, operational alerting — cases where latency in seconds matters |
| Batch | Financial reporting, regulatory audits, historical analytics — where full-fidelity and cost efficiency matter more than speed |
Apache Flink has become the de facto engine for stateful stream processing. Unlike Spark Structured Streaming (micro-batch), Flink processes event-by-event with sub-second latency. Confluent Cloud now offers managed Flink, reducing adoption friction.
Data Virtualization as an alternative processing pattern: For enterprises running heterogeneous estates spanning on-premises Oracle, SAP, and legacy databases alongside cloud platforms, full physical data movement into a lakehouse is often neither practical nor desirable. Data virtualization platforms address this through a logical query layer that presents disparate sources as a unified virtual data model — without data movement. Key characteristics: zero-copy query pushdown, real-time access to operational systems, unified logical schema, row/column-level masking, and end-to-end lineage from source to consumer.
In a modern architecture, a data virtualization layer complements — rather than replaces — the lakehouse: the lakehouse holds curated historical analytical data at scale, while virtualization provides governed real-time access to operational systems that cannot or should not be replicated.
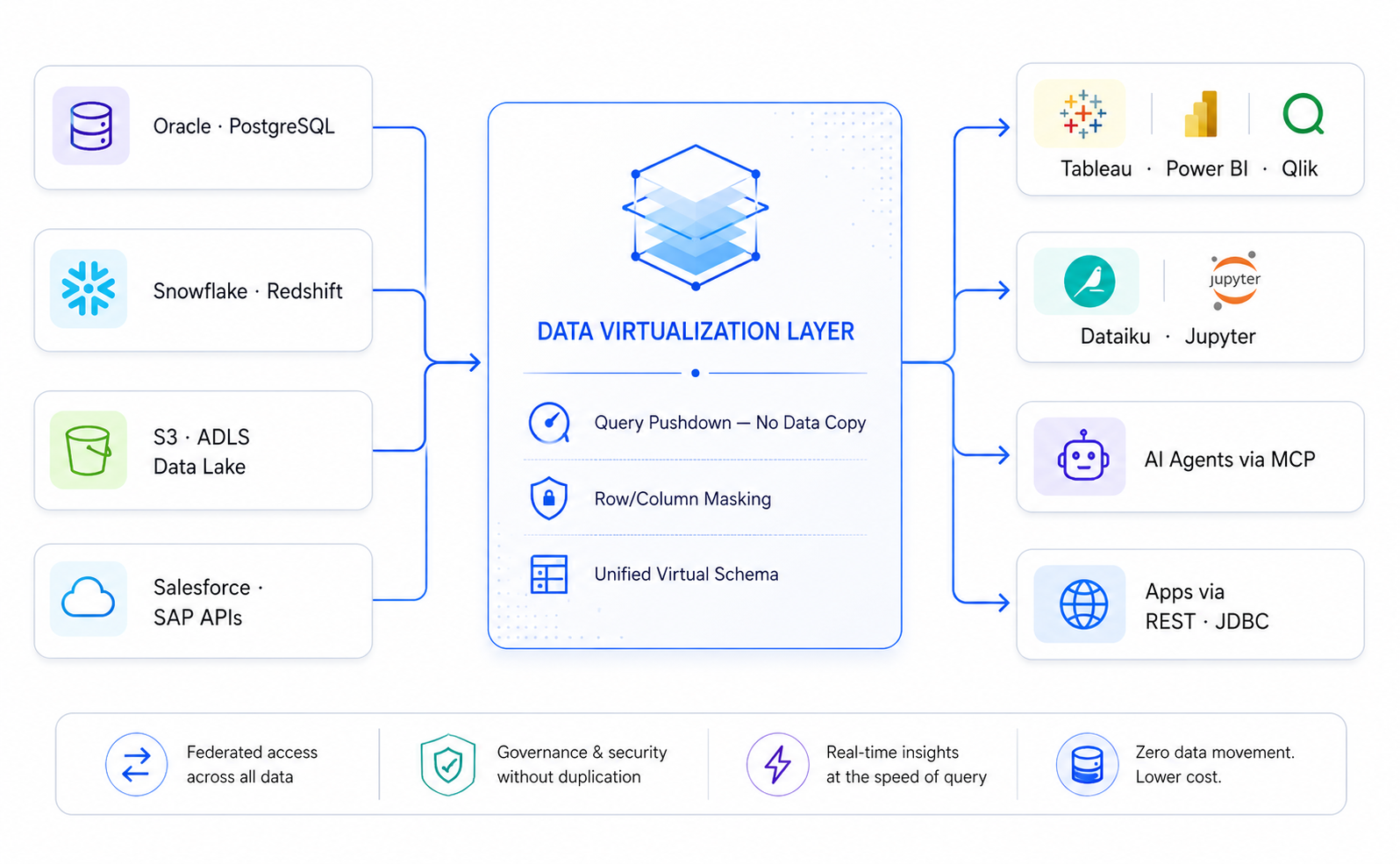
Data Virtualization Layer for Federated Query
Layer 4: Transformation and the Semantic Layer
The semantic layer sits between raw data and consumption tools (BI dashboards, notebooks, AI assistants) and defines business logic — metrics, entities, relationships, time logic — in one authoritative place. Without a semantic layer, LLMs asked to generate SQL on ambiguous business terms hallucinate. With a well-defined semantic layer, text-to-SQL accuracy improves from 20–40% to 83–92% (per documented benchmarks on Spider and BIRD datasets).
Three architectural patterns in 2026:
- BI-native: LookML, Power BI DAX, Tableau Semantics
- Platform-native: Snowflake Semantic Views, Databricks Unity Catalog Metric Views, dbt Semantic Layer (MetricFlow)
- Universal/headless: Cube, AtScale, GoodData — tool-agnostic semantic hubs
Important distinction: Snowflake Cortex = AI/ML functions (LLM access, ML, vector search). Snowflake Semantic Views = the semantic layer. These are separate products — conflating them is a common error.
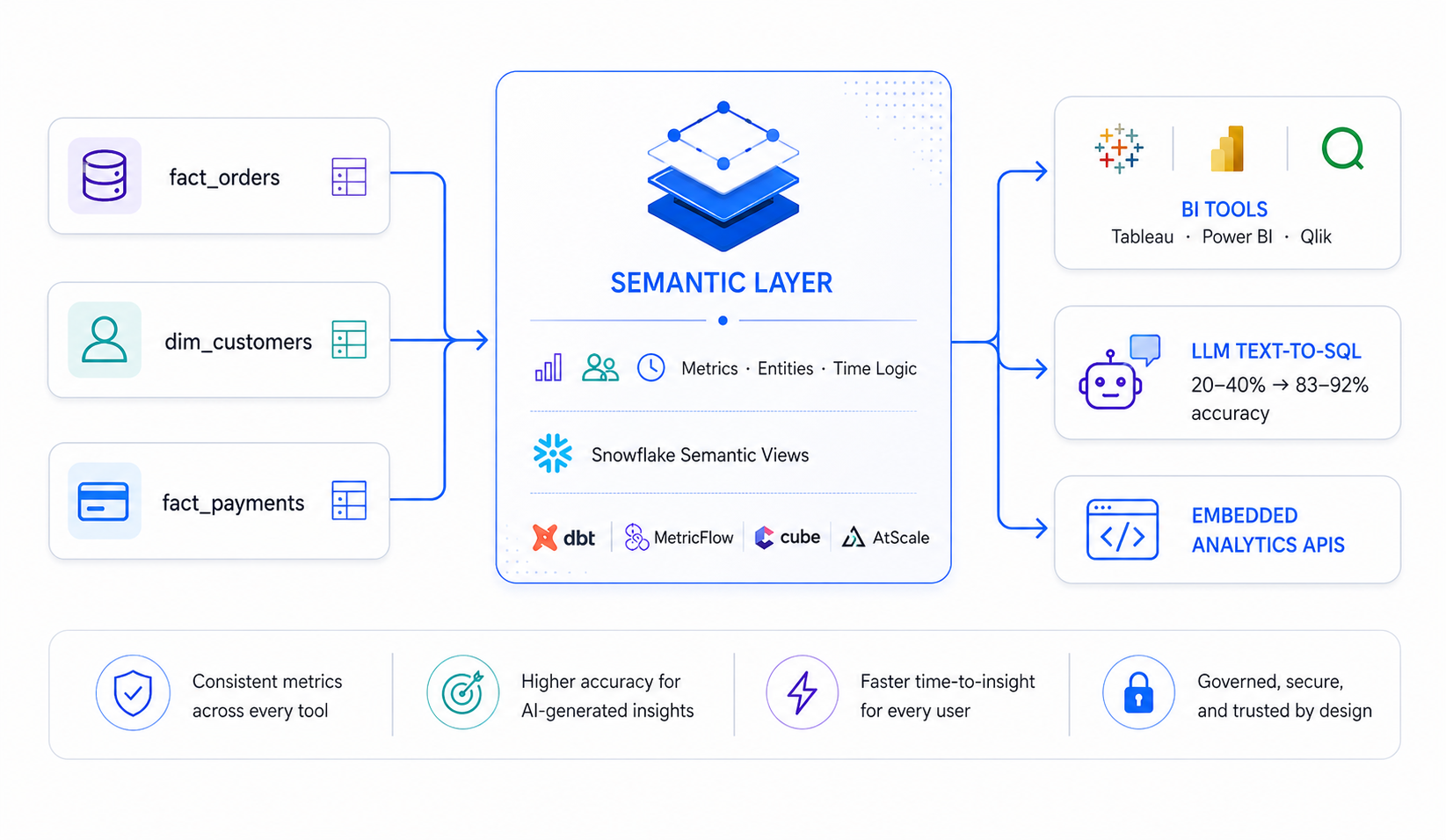
The Semantic Layer
Layer 5: Governance and Compliance
Governance is no longer optional infrastructure. In Singapore and across APAC, two regulatory frameworks directly shape platform architecture:
- Singapore PDPA: Data protection by design, mandatory DPO, breach notification within 3 business days for significant breaches. Fines up to 10% of annual Singapore turnover.
- MAS frameworks — two distinct instruments:
- MAS TRM Guidelines (January 2021): Board-level technology risk oversight, cyber resilience, cloud service provider risk management.
- MAS Data Governance Guidelines (February 2024): Data quality controls, data lineage, and CDO accountability for MAS-regulated institutions.
- Both frameworks, aligned with BCBS 239, require technical enforcement built into platform architecture — not just documented policy.
Enterprise data catalogs — such as Alation, Collibra, or Atlan — operationalize governance by connecting policy intent to the actual data estate. Key functions: auto-discovery across connected platforms, end-to-end lineage (source → ETL → transformation → BI report), business glossary stewardship, query intelligence for data trust, and compliance reporting for DPO and MAS regulatory examinations. A data catalog is not a point-solution monitoring tool — it is the governance intelligence layer spanning all other layers.
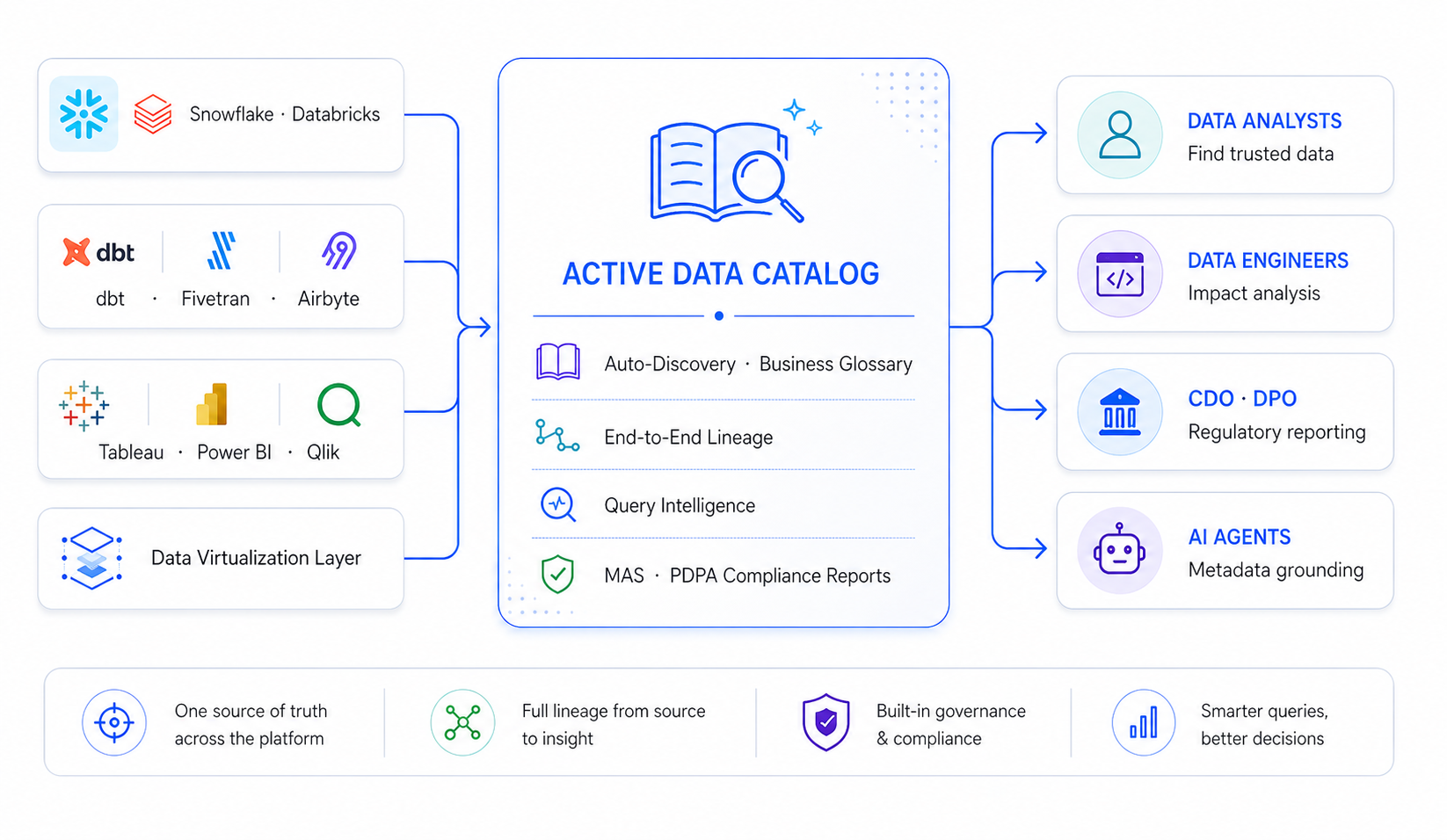
Data Governance For All Layers
Layer 6: Data Observability
Observability has evolved from a monitoring add-on into the control plane for enterprise AI and data governance. A good observability layer monitors data freshness, volume anomalies, schema changes, distribution drift, and pipeline failures with lineage-aware impact analysis.
In 2026, open-source tooling — Soda Core, Elementary, dbt Tests — has democratized capabilities previously locked behind enterprise platforms. The convergence of data quality testing and observability is establishing a new expectation: reliable, transparent pipelines verified the same way modern software systems are.
AI output observability is the newest frontier: as AI models consume platform data, observability must extend to monitoring whether data served to models is accurate, fresh, and consistent with semantic definitions. Platforms like Monte Carlo and Soda are extending into AI pipeline observability use cases in 2025–2026.
3. The AI-Ready Dimension
The critical 2026 distinction for any data platform is AI readiness — not just analytics capability, but the ability to serve AI and GenAI workloads reliably at scale.
An AI-ready platform has five characteristics that older BI-centric platforms typically lack:
- Metadata-driven pipelines with automated schema inference and self-healing
- Vector database compatibility for RAG workloads — Pinecone, Weaviate, pgvector, or platform-native vector stores
- Feature store integration for ML teams to share, reuse, and version features consistently
- Real-time or near-real-time data availability for models needing fresh context
- Strong data lineage and provenance for AI output explainability and audit
Agentic AI — the 2025–2026 frontier: The shift from single-prompt LLM calls to multi-step AI agents introduces new platform requirements:
- Structured tool APIs: AI agents call structured APIs — platforms need well-documented REST APIs or MCP servers exposing data assets
- Model Context Protocol (MCP): Released by Anthropic in late 2024 as an open standard for connecting AI agents to data sources. By 2026, MCP has been adopted by Snowflake, Databricks, Confluent, and Tableau. An AI-ready platform should expose MCP-compatible endpoints
- Audit trails for agentic actions: Immutable logs when AI agents read, write, or transform data — critical for MAS TRM and PDPA compliance
- Context window management: Semantic layers and metadata catalogs are essential for scoping retrieval to governed, relevant data
4. Architecture Patterns: Lakehouse, Mesh, or Fabric?
| Architecture | Core Idea | Best For | Trade-off |
|---|---|---|---|
| Data Lakehouse | Unified storage combining lake flexibility with warehouse governance | Single-platform organizations; AI/ML-heavy workloads | Can become a data swamp without strong governance |
| Data Mesh | Decentralized, domain-owned data products | Large enterprises with independent business units and strong data literacy | Requires cultural change; cross-domain governance is challenging |
| Data Fabric | Unified integration layer connecting diverse sources through metadata-driven discovery | Hybrid/multi-cloud; fragmented data estates | Higher platform complexity; requires robust metadata management |
By 2025–2026, the consensus is that Data Mesh + Data Fabric synergy is the emerging enterprise pattern — decentralized domain ownership combined with a unified integration and governance fabric. Data virtualization is the most widely deployed concrete implementation of the Data Fabric concept in enterprise APAC.
Microsoft Fabric (GA November 2023) occupies a distinct fourth position: a deeply integrated SaaS analytics platform bundling OneLake, Synapse Data Engineering, Data Factory, Real-Time Analytics, Power BI, and Data Science in a single licensed product. For Microsoft-centric organizations already on Azure/M365, Fabric is a compelling consolidation path — particularly relevant in APAC mid-market and government sectors.
For mid-market APAC enterprises, the lakehouse remains the most practical starting point before evolving toward mesh principles as data maturity grows.
5. The 2026 Technology Toolkit Reference
| Category | Leading Tools (2026) | Notes |
|---|---|---|
| Cloud Data Warehouse / Lakehouse | Snowflake, Databricks, BigQuery, Redshift, Microsoft Fabric | Snowflake and Databricks dominant in enterprise APAC; Fabric growing in Microsoft shops |
| Open Table Format | Apache Iceberg, Delta Lake, Apache Hudi, Apache Polaris Catalog | Iceberg emerging as universal standard; Polaris enables multi-engine Iceberg governance |
| Streaming / Event Processing | Confluent Kafka, Apache Flink, Debezium (CDC), Redpanda | Kafka dominant; Flink for real-time stateful transforms |
| ELT Ingestion Connectors | Fivetran, Airbyte, Stitch | Managed connector layer largely absent from pre-2022 architectures |
| Transformation / Modeling | dbt Core, dbt Cloud, Coalesce | dbt widely adopted; dbt Semantic Layer (MetricFlow) critical for AI readiness |
| Orchestration | Apache Airflow, Prefect, Dagster | Airflow most common; Dagster gaining in modern stacks |
| BI / Analytics | Tableau, Power BI, Qlik | All major platforms now embedding AI-native capabilities (see Section 7) |
| Semantic Layer | Snowflake Semantic Views, dbt Semantic Layer, Cube, AtScale, LookML | Critical for AI readiness; Snowflake Cortex ≠ semantic layer |
| Data Observability | Monte Carlo, Soda Core, Elementary, Collibra DQ | Consolidating into platform-wide solutions |
| Data Catalog / Governance | Alation, Collibra, Atlan, Databricks Unity Catalog, OpenMetadata | OpenMetadata growing as open-source option |
| Vector Database (AI / RAG) | Pinecone, Weaviate, pgvector, Snowflake Cortex Vector Search, Databricks Vector Search | Required for RAG/GenAI workloads |
| AI Agent Connectivity | MCP servers, REST APIs, GraphQL | Standard interface for AI agents to interact with data platform resources |
| Data Virtualization / Data Fabric | Denodo (enterprise leader, APAC-relevant), Tibco Data Virtualization | Zero-copy federated access; PDPA/MAS-compliant masking at the virtual layer |
| Federated Query | Trino, Starburst, Databricks Unity Catalog Federation | SQL-native federated queries; lighter-weight than full virtualization |
6. APAC-Specific Considerations
Regulatory compliance architecture:
- Singapore PDPA and MAS TRM Guidelines (2021) together with MAS Data Governance Guidelines (2024) require data residency controls, breach notification infrastructure, end-to-end lineage tracking, and board-level governance oversight — built into platform architecture, not just documented in policy
- MAS-regulated institutions must implement data lineage and quality controls aligned with BCBS 239 — the platform must technically support these requirements
- Cross-border data flows across ASEAN require explicit data classification and transfer mechanisms embedded in the governance layer
- The 3-business-day breach notification window under PDPA requires automated breach detection and alerting in the platform to be operationally achievable
Vendor selection context:
- Snowflake (Singapore AWS region) and Databricks (Singapore Azure/AWS regions) are the dominant cloud lakehouse platforms in APAC enterprise accounts
- Microsoft Fabric is available in Australia and Japan Azure regions (Singapore expansion expected); relevant for Microsoft-centric APAC enterprises
- Multi-cloud and hybrid-cloud are preferred by regulated industries (FSI, healthcare, government) in Singapore for data sovereignty management
- Huawei Cloud (Singapore region) is relevant for enterprises with Greater China operations — Huawei MRS, DWS, and OBS can be positioned in multi-cloud architectures alongside Databricks or Snowflake for sovereignty-sensitive workloads
7. The BI-First Trap — And Why Even BI Tools Have Evolved Past It
Most mid-market APAC enterprises built their platforms around a BI-first model: a data warehouse, some ETL pipelines, and a BI tool. That architecture fails on three dimensions relevant to 2026 buyers:
- Not AI-ready — no vector compatibility, no feature store, no semantic layer for LLMs, no MCP-compatible APIs for agentic workloads
- Batch-only — buyers now expect real-time for key operational cases (fraud, personalization, operational monitoring)
- Governance on paper only — MAS TRM (2021) and MAS Data Governance Guidelines (2024) both require technical enforcement, not just documented policy
The important nuance: this critique targets the architecture built around BI tools, not the BI tools themselves. The major BI platforms have moved aggressively beyond passive dashboards.
Tableau illustrates this shift clearly: Tableau Pulse delivers proactive AI-powered metric monitoring and anomaly alerts to stakeholders via email, Slack, and mobile — no dashboard visit required. Tableau Next introduces agentic AI layers including the Data Pro Agent (exploratory data analysis through conversation), Concierge Agent (business user natural language Q&A), and Inspector Agent (data quality validation). Tableau Next MCP bridges LLMs directly to Tableau data and actions, making Tableau a first-class data source for agentic AI workflows. Power BI and Qlik are on parallel trajectories — Copilot integration in Power BI and Qlik's Associative AI bring similar AI-augmentation into their platforms.
The issue is not that BI tools are obsolete. The issue is that deploying any BI tool on top of an unreformed 2021-era architecture — batch-only ingestion, no semantic layer, no governance enforcement, no real-time capability — means the AI features have no foundation to stand on. A Tableau Pulse alert is only as good as the freshness of the underlying pipeline. A Tableau Agent is only as reliable as the semantic layer defining the metrics it reasons over.
The 2026 upgrade path is not "replace your BI tool." It is: fix the platform below the BI tool, then let the BI tool's AI capabilities compound on a solid foundation.
8. The Role of Tiered Partner Ecosystems in Platform Delivery
A modern data platform architecture is rarely delivered by a single vendor or a single integrator. In practice, APAC enterprises navigate a layered partner ecosystem where system integrators bring complementary vendor depth that no single OEM can provide.
This is structurally important for mid-market APAC buyers, who typically lack the internal bench strength to evaluate, integrate, and operate multi-tool architectures spanning ingestion, lakehouse, transformation, governance, and AI. Experienced integrators — particularly those with tiered vendor relationships across these categories — serve as the practical bridge between architecture on paper and platforms running in production.
What tiered vendor partnerships mean in practice: Partners with deep, certified relationships across multiple complementary vendors can offer something individual vendors cannot: cross-stack integration expertise. A partner with Tier 1 depth in BI (Tableau), data lakehouse (Databricks, Snowflake), data virtualization (Denodo), data governance (Alation), and AI/ML platforms (Dataiku) can design and deliver a cohesive architecture rather than a collection of independently procured tools.
Illustrative partner capability patterns relevant to APAC deal architectures:
| Deal Pattern | Typical Stack | Relevant Partner Depth |
|---|---|---|
| Tableau-only analytics upgrade | Tableau Cloud / Server + Tableau Pulse / Next | Tableau implementation + AI integration capability |
| Full-stack data modernization | Snowflake or Databricks + Fivetran + dbt + Tableau | Cross-lakehouse and BI integration expertise |
| Hybrid cloud + analytics | On-prem DWS or Data Lake + Denodo + Alation + Tableau/Qlik | Multi-cloud, data virtualization, governance |
| AI/ML platform deployment | Dataiku or Databricks + data integration layer | AI/ML platform delivery + pipeline integration |
| Data governance & compliance | Alation + Securiti + data platform | Catalog, privacy, and lineage implementation |
| Data fabric / virtualization | Denodo + governance layer | Zero-copy federation across fragmented estates |
For APAC buyers evaluating data platform investments, the partner's vendor portfolio breadth and certified delivery experience across complementary layers is as material a selection criterion as the individual product capabilities — especially when regulatory compliance (PDPA, MAS) requires cross-layer technical enforcement that no single OEM fully delivers out of the box.
Looking for help mapping out your data architecture? Drop an email to [email protected]